
Model 3D Detection and Tracking using C++
The CV3D API provides algorithms to detect and track a 3D object for which the geometry is known. It operates on 2D data from Prophesee event-based camera.
The sample metavision_model_3d_tracking.cpp shows how to:
load a 3D model from a file, the 3D object being described using a simple JSON format
use algorithms to detect and track the object from the events stream
dynamically adapt the size of the time slices to suit the algorithms’ needs
visualize the tracked object in the events stream
Thanks to the simple 3D object representation, the algorithms are also capable of detecting and tracking fiducial markers that are widely used in AR/VR applications.
The source code of this sample can be found in <install-prefix>/share/metavision/sdk/cv3d/cpp_samples/metavision_model_3d_tracking
when installing Metavision SDK from installer or packages. For other deployment methods, check the page
Path of Samples.
Warning
Our 3D object tracking algorithm is a first evaluation version that would require more robustification and characterization to be used in production. Though, it should be useful to assess what an event-based sensor can do in this field. If you want to elaborate on this algorithm, you can contact us to discuss your project and get the source code with our Metavision SDK Pro offer.
Expected Output
This sample outputs the pose of the camera with respect to the known object.
Setup & requirements
The tracking algorithm relies on the capacity to track the edges of an object. As a result, here are some conditions that are important to fulfill to be able to robustly track that object:
the edges defined in the 3D model JSON file should precisely match those of the object
the contrast at the edges should be strong enough to trigger events in the event-based sensor
there should not be too much texture or other edges near the object’s edges (both in the background and on the object itself)
How to start
To run this sample, you will need to provide:
a RAW file containing a sequence in which the 3D object to be tracked appears (offline mode),
a JSON file containing the description of the 3D object
a JSON file containing an initialization camera pose (pose from which the detection algorithm will try to detect the object),
a JSON file containing the calibration of the camera used for the record (or the camera used in live mode)
Optionally, you can also provide a camera settings file when the sample is executed in live mode to tune the biases for this application.
Note
The description of the 3D object must contain:
a list of all the 3D object’s vertices
a list of all the 3D object’s edges, an edge being a pair of two indices pointing to its vertices
a list of all the 3D object’s faces that themselves consist in:
a list of indices pointing to each edge of the face,
the face’s normal in the object’s coordinate system
Note
Take a look at one of the Sample Recordings provided for this sample for more details about these files.
To run the sample, first, compile the sample as described in this tutorial.
Then, to start the sample based on the live stream from your camera, run:
Linux
./metavision_model_3d_tracking -i <base_path>/object
Windows
metavision_model_3d_tracking.exe -i <base_path>/object
where <base_path> is a path to a folder containing the following files:
. └── <base_path> ├── calibration.json ├── model_init_pose.json └── object.json
If you want to provide a camera settings file (e.g. to tune the biases),
use the command above with the additional option --input-camera-config (or -j) with a JSON file containing the settings.
To create such a JSON file, check the camera settings section.
If you want to start the sample using a RAW file, run:
Linux
./metavision_model_3d_tracking -r <base_path>/object.raw
Windows
metavision_model_3d_tracking.exe -r <base_path>/object.raw
where <base_path> is a path to a folder containing the following files:
. └── <base_path> ├── calibration.json ├── model_init_pose.json ├── object.json └── object.raw
To check for additional options:
Linux
./metavision_model_3d_tracking -h
Windows
metavision_model_3d_tracking.exe -h
Note
If tracking gets lost sometimes, you can try to adjust those tracking parameters:
--n-events N_EVENTS: number of events after which a tracking step is attempted. (default: 5000)
--n-us N_US: amount of time after which a tracking step is attempted. (default: 10000)
Note that smaller n-events or n-us makes algorithm more robust to higher speed motion but slower (latency increases)
as well. So to make it faster, make sure your sensor biases are tuned correctly for your application, and you might want to filter out
events with activity filter or trail filter for example.
The tracking algorithm is not compatible with spherical objects because they don’t provide “true physical edges”. Meaning that the 3D location of their edges is never the same as it depends on the view point from which they are observed. Hence, the tracking algorithm can only be used to track 3D objects for which true edges exist.
The detection algorithm can take more time with a large number of faces or high background noise. In this situation, you should try to use the most simplified 3D model possible (but still with accurate true edges). The more faces you use, the less efficient the detection and tracking algorithm will be.
The same holds for the background noise: you should try to reduce it as much as possible. Indeed not only noise makes the algorithms slower but also it makes them less robust, especially the tracking algorithm which is very sensitive to noise. Depending on the speed of your objects (especially for high-speed objects), you might have to tune the sensor biases to get better data. Using some filtering and/or Region of Interest (ROI) may help to speed up the detection algorithm and reduce the latency.
Code Overview
Processing Pipeline
Before detecting and tracking a 3D object, the first step is to load its 3D representation. This is done using the
Metavision::load_model_3d_from_json() function:
if (!Metavision::load_model_3d_from_json(config.model_path, model_))
throw std::runtime_error("Impossible to load the 3D model from " + config.model_path);
Then the Metavision::Model3dDetectionAlgorithm and Metavision::Model3dTrackingAlgorithm can
be instantiated with:
a reference to a
Metavision::CameraGeometryBaseinstancea reference to a
Metavision::Model3dinstancea reference to a
Metavision::MostRecentTimestampBufferTinstance that they will fill with the input events buffers
detection_algo_ = std::make_unique<Metavision::Model3dDetectionAlgorithm>(*cam_geometry_, model_, time_surface_,
config.detection_params_);
tracking_algo_ = std::make_unique<Metavision::Model3dTrackingAlgorithm>(*cam_geometry_, model_, time_surface_,
config.tracking_params_);
This sample implements the following basic state machine:
Both algorithms process time slices of events and output the new camera’s pose in case of success. Those time slices can be created according to different strategies (i.e. fixed number of events, fixed duration or a mixed condition). Each of these two algorithms has a more appropriate way of receiving events.
The Metavision::Model3dTrackingAlgorithm is meant to track an object while the user is moving very fast. To
track that object during fast motions the algorithm relies on the camera’s high temporal resolution which makes the
object very close from its previous location from one step to another. This hypothesis enables the implementation of
very efficient methods (that still remain valid for slow motions). As a consequence, to work correctly, this
algorithm has to be called at a high frequency when the user is moving fast but can be called at a very low frequency
when the user is moving slowly. One way to get this behavior is to feed the algorithm with time slices having a fixed
number of events. By doing so, the output camera poses frequency automatically adapts to the camera’s speed.
In contrast to the Metavision::Model3dTrackingAlgorithm, the
Metavision::Model3dDetectionAlgorithm algorithm is meant to detect an object that is not necessarily very
close from its initialization pose while the user is moving relatively slowly. The former point implies that we can no
longer rely on the close locality hypothesis and thus have to rely on more costly methods to detect that object.
However, the latter point implies that the algorithm can be called at a relative low frequency which compensates its
extra cost. As a result, big fixed duration time slices (e.g. 10ms) are well suited for this algorithm.
To address this, the algorithms could have been implemented in an asynchronous way, each producing its result (i.e. calling the asynchronous output callback) according to its configuration (i.e. N events, N us or mixed), but this would have made the synchronization between them complicated during state changes.
Instead, the problem is solved upstreams by putting a Metavision::SharedEventsBufferProducerAlgorithm
between the camera and the algorithms and whose configuration can be changed at runtime. Here is the pipeline
implemented in the sample:
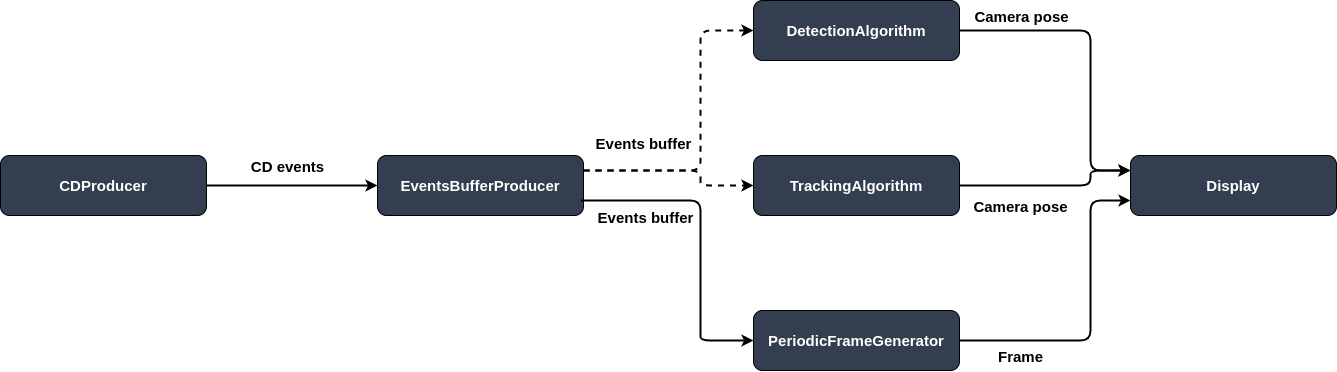
For technical reasons, further detailed in the code, the produced buffers cannot directly be processed in the
Metavision::SharedEventsBufferProducerAlgorithm’s output callback. As a consequence, when the output
callback is called, the produced buffer is pushed into a queue so that it can be processed later:
Metavision::SharedEventsBufferProducerParameters params;
auto cb = [&](Metavision::timestamp ts, const Buffer &b) { buffers_.emplace(b); };
producer_ = std::make_unique<Metavision::SharedCdEventsBufferProducerAlgorithm>(params, cb);
In the camera’s callback, events are first processed by the producer and then the time slices, that may have been
produced meanwhile, are processed by the Metavision::Model3dDetectionAlgorithm and
Metavision::Model3dTrackingAlgorithm.
void cd_processing_callback(const Metavision::EventCD *begin, const Metavision::EventCD *end) {
if (evt_filter_) {
filtered_evts_.clear();
evt_filter_->process_events(begin, end, std::back_inserter(filtered_evts_));
producer_->process_events(filtered_evts_.cbegin(), filtered_evts_.cend());
} else {
producer_->process_events(begin, end);
}
process_buffers_queue();
}
And the full buffers queue processing loop:
while (!buffers_.empty()) {
const bool prev_is_tracking = is_tracking_;
const auto buffer = buffers_.front();
buffers_.pop();
const auto begin = buffer->cbegin();
const auto end = buffer->cend();
if (is_tracking_) {
is_tracking_ = tracking_algo_->process_events(begin, end, T_c_w_);
} else {
if (detection_algo_->process_events(begin, end, T_c_w_, &visible_edges_, &detected_edges_)) {
// we wait for several consecutives detections before considering the model as detected to avoid
// false positive detections
is_tracking_ = (++n_detection_ > config_.n_detections_);
} else {
n_detection_ = 0;
}
}
// the frame generation algorithm processing can trigger a call to show_async which can trigger a reset of
// the tracking if the space bar has been pressed.
frame_generation_algo_->process_events(begin, end);
if (prev_is_tracking != is_tracking_) {
if (is_tracking_)
set_tracking_params(std::prev(buffer->cend())->t); // triggers the creation of a new buffer
else
set_detection_params(); // triggers the creation of a new buffer
}
if (evt_filter_)
update_filtering_params();
}
Note
We can note from the code that we do not switch to the tracking state as soon as the object is detected. Instead, we
wait for N successive detections to reduce false positive ones.
Note
In the sample, the tracking can also be reset by pressing the space bar key
Both the detection algorithm and the tracking algorithm proceed as follows:
visible edges of the model are recovered,
points are sampled along each edge, called support points,
matches for each support point are searched for in the timesurface,
the associations of points and matches are used in a Gauss-Newton optimization to compute the pose of the camera in relation to the model.
Matches are determined by searching, along the normal of the edge, for the pixel with the latest timestamp. Point-match associations are weighted in relation to the most recent timestamp in the lot. Default weights for the most recent and oldest timestamp can be changed in the pipeline parameters.
Tracking step during an overall vertical movement
The timesurface is pseudo-colored from most-recent timestamp (red) to oldest allowed timestamp (dark blue). A pink line is drawn for each support point, representing the area of search. Green points denote good matches and red points denote no match.
For the detection step, matches are further confirmed by checking that the optical flow at those locations matches the expected flow, determined by the edge normal.
Note
If you experience latency in your tracking you can try to reduce the parameter --tracking-search-radius to limit the search for matches to closer pixels, or increase the parameter
--tracking-support-point-step to increase the inter-distance between support points, and therefore reduce their overall number. That could however make the tracking less robust.
Reciprocally, if the tracking gets lost, you can try to increase the parameter --tracking-search-radius to expand the search for matches to more pixels, and/or reduce
the parameter --n-events so that less events are processed between tracking steps and so the marker would have moved a lesser distance. That could however increase
the latency of the overall pipeline.
Display
For the display we use the Metavision::PeriodicFrameGenerationAlgorithm asynchronous algorithm which
generates frames from events at a fixed frame rate. When a new frame is available we draw the model’s edges on top of it
using the last known camera’s pose. When the pipeline is in the detection state, tracked and non tracked edges are
drawn using different colors:
void frame_callback(Metavision::timestamp ts, cv::Mat &frame) {
cv::putText(frame, std::to_string(ts), cv::Point(0, 10), cv::FONT_HERSHEY_DUPLEX, 0.5,
(is_tracking_ ? cv::Scalar(0, 255, 0) : cv::Scalar(0, 0, 255)));
// Be careful, here the events and the 3D model are not rendered in a tightly synchronized way, meaning that
// some shifts might occur. However, most of the time they should not be noticeable
if (is_tracking_) {
Metavision::select_visible_edges(T_c_w_, model_, visible_edges_);
Metavision::draw_edges(*cam_geometry_, T_c_w_, model_, visible_edges_, frame, cv::Scalar(0, 255, 0));
cv::putText(frame, "tracking", cv::Point(0, 30), cv::FONT_HERSHEY_DUPLEX, 0.5, cv::Scalar(0, 255, 0));
} else {
Metavision::draw_edges(*cam_geometry_, T_c_w_, model_, visible_edges_, frame, cv::Scalar(0, 0, 255));
Metavision::draw_edges(*cam_geometry_, T_c_w_, model_, detected_edges_, frame, cv::Scalar(0, 255, 0));
cv::putText(frame, "detecting", cv::Point(0, 30), cv::FONT_HERSHEY_DUPLEX, 0.5, cv::Scalar(0, 0, 255));
}
if (evt_filter_)
cv::circle(frame, cv::Point(model_center_(0), model_center_(1)), static_cast<int>(model_radius_),
cv::Scalar(150, 0, 255), 1);
if (video_out_)
video_out_->write(frame);
if (window_)
window_->show_async(frame);
}
Warning
As pointed out in the code, the background frame and the 3D model’s edges may not be perfectly aligned. However this should be imperceptible in practice.