
Training a Classification Model
Introduction
In this tutorial, we will show you how to train a Rock-paper-scissors classifier with the supervised classification module of Metavision ML. We will walk you through the whole training pipeline, from data acquisition to model deployment.
Dataset
We use Chifoumi dataset, recorded with Prophesee EVK1 Gen3.1 (VGA). The dataset contains in total 2576 samples, each of which captures a motion sequence of gesture entering and leaving the scene. The data is collected under the following conditions:
3 different speed: slow, normal, fast
with left and right hand
10-50 cm distance to the camera
20 recordings contains flickering
The data was first auto-labeled based on the event rate and then corrected manually. Let’s take a quick look at the data.
import os
import numpy as np
import torch
from metavision_core.event_io import EventsIterator
from metavision_sdk_core import BaseFrameGenerationAlgorithm
import cv2
Load one data sample
DAT_FILE = /pah/to/chifoumi/scissors_right_close_slow_standing_recording_020_2021-09-14_15-10-27_cd.dat
label_file = DAT_FILE.split("_cd.dat")[0] + "_bbox.npy" # leveraging default EventBbox format, no bbox is required
assert os.path.isfile(label_file), "check your label input path!"
assert os.path.isfile(DAT_FILE), "check your DAT input path!"
LABEL_DICT = {"0": "paper", "1": "rock", "2": "scissor"}
VIZ_WINDOW = "Data Sample Visualization"
Construct a frame based on annotation frequency
def get_delta_t(npy_data):
deltaTs = npy_data["ts"][1:] - npy_data['ts'][:-1]
delta_t = np.unique(deltaTs).item()
return delta_t
labels = np.load(label_file)
deltaT = get_delta_t(labels)
mv_it = EventsIterator(DAT_FILE, delta_t=deltaT)
height, width = mv_it.get_size()
img = np.zeros((height, width, 3), dtype=np.uint8)
cv2.namedWindow(VIZ_WINDOW)
for idx, ev in enumerate(mv_it):
BaseFrameGenerationAlgorithm.generate_frame(ev, img)
t = mv_it.get_current_time()
if t in labels["ts"]:
label = LABEL_DICT[str(labels[labels['ts']==t]['class_id'].item())]
cv2.putText(img, label, (10, img.shape[0] - 20), cv2.FONT_HERSHEY_SIMPLEX, 2, (0,0, 255))
cv2.imshow(VIZ_WINDOW, img)
cv2.waitKey(50)
cv2.destroyWindow(VIZ_WINDOW)
## Model architecture
The model architecture is quite similar to the detection model described in Train Detection Tutorial, except that we only need a classifier head in the end.
Train with Pytorch lightning
To reduce your development time, we’ve created a Python sample train_classification.py, which allows you to train, fine-tune an EB classification model based on precomputed HDF5 dataset. The training pipeline is set up based on PyTorch Lightning framework. You need to split your whole dataset into 3 subsets: train, dev, and test. See details in Python sample train_classification.py.
Let’s see what you can do with this training module:
python train_classification.py --help
usage: train_classification.py [-h] [--lr LR]
[--lr_scheduler_step_gamma LR_SCHEDULER_STEP_GAMMA]
[--batch_size BATCH_SIZE] [--delta-t DELTA_T]
[--wd WD] [-w WEIGHTS [WEIGHTS ...]]
[--val_every VAL_EVERY]
[--demo_every DEMO_EVERY]
[--save_every SAVE_EVERY]
[--max_epochs MAX_EPOCHS] [--just_val]
[--just_test] [--just_demo] [--resume]
[--checkpoint CHECKPOINT]
[--precision PRECISION] [--cpu]
[--limit_train_batches LIMIT_TRAIN_BATCHES]
[--limit_val_batches LIMIT_VAL_BATCHES]
[--limit_test_batches LIMIT_TEST_BATCHES]
[--accumulate_grad_batches ACCUMULATE_GRAD_BATCHES]
[--fast_dev_run] [--finetune]
[--height_width HEIGHT_WIDTH HEIGHT_WIDTH]
[--num_tbins NUM_TBINS]
[--classes CLASSES [CLASSES ...]]
[--num_workers NUM_WORKERS] [--skip_us SKIP_US]
[--label_delta_t LABEL_DELTA_T]
[--use_nonzero_labels]
[--disable_data_augmentation]
[--train_plus_val]
[--models {ConvRNNClassifier,LeNetClassifier}]
[--feature_base FEATURE_BASE]
[--feature_channels_out FEATURE_CHANNELS_OUT]
[--no_window]
[--show_plots {cm,pr,roc} [{cm,pr,roc} ...]]
[--inspect_result]
root_dir dataset_path
positional arguments:
root_dir logging directory
dataset_path path
optional arguments:
-h, --help show this help message and exit
--lr LR learning rate (default: 0.0001)
--lr_scheduler_step_gamma LR_SCHEDULER_STEP_GAMMA
learning rate scheduler step param (disabled if None)
(default: None)
--batch_size BATCH_SIZE
batch size (default: 4)
--delta-t DELTA_T timeslice duration in us (default: 10000)
--wd WD weight decay (default: 1e-05)
-w WEIGHTS [WEIGHTS ...], --weights WEIGHTS [WEIGHTS ...]
list of weights for each class (default: [])
--val_every VAL_EVERY
validate every X epochs (default: 1)
--demo_every DEMO_EVERY
run demo every X epoch (default: 2)
--save_every SAVE_EVERY
save checkpoint every X epochs (default: 1)
--max_epochs MAX_EPOCHS
train for X epochs (default: 200)
--just_val run validation on val set (default: False)
--just_test run validation on test set (default: False)
--just_demo run demo video with trained network (default: False)
--resume resume from latest checkpoint (default: False)
--checkpoint CHECKPOINT
resume from specific checkpoint (default: )
--precision PRECISION
mixed precision training default to float16 (default:
16)
--cpu use cpu (default: False)
--limit_train_batches LIMIT_TRAIN_BATCHES
limit train batches to fraction of dataset (default:
1.0)
--limit_val_batches LIMIT_VAL_BATCHES
limit val batches to fraction of dataset (default:
1.0)
--limit_test_batches LIMIT_TEST_BATCHES
limit test batches to fraction of dataset (default:
1.0)
--accumulate_grad_batches ACCUMULATE_GRAD_BATCHES
accumulate gradient for more than a single batch
(default: 1)
--fast_dev_run run a single batch (default: False)
--finetune finetune from checkpoint (default: False)
--height_width HEIGHT_WIDTH HEIGHT_WIDTH
if set, downsize the feature tensor to the
corresponding resolution using interpolation (default:
None)
--num_tbins NUM_TBINS
timesteps per batch for truncated backprop (default:
12)
--classes CLASSES [CLASSES ...]
subset of classes to use (default: [])
--num_workers NUM_WORKERS
number of threads (default: 2)
--skip_us SKIP_US skip this amount of microseconds (default: 0)
--label_delta_t LABEL_DELTA_T
delta_t of annotation in (us) (default: 10000)
--use_nonzero_labels if set, only use labels which are non-zero (default:
True)
--disable_data_augmentation
Disable data augmentation during training (default:
True)
--train_plus_val if set, train using train+val, test on test (default:
False)
--models {ConvRNNClassifier,LeNetClassifier}
model architecture type (default: ConvRNNClassifier)
--feature_base FEATURE_BASE
growth factor of feature extractor (default: 16)
--feature_channels_out FEATURE_CHANNELS_OUT
number of channels per feature-map (default: 128)
--no_window Disable output window during demo (only write a video)
(default: False)
--show_plots {cm,pr,roc} [{cm,pr,roc} ...]
select evaluation plots on test datasets (default:
['cm', 'pr', 'roc'])
--inspect_result Inspect sequential results together with their
recording frames (default: False)
## KPIs
Once the model is trained with train/val dataset, you can evaluate your model on your test dataset using the --just_test parameter with the following KPIs: confusion matrix, PR-curve and ROC curve.
The KPIs of the pre-trained Chifoumi model on the test dataset are illustrated below.
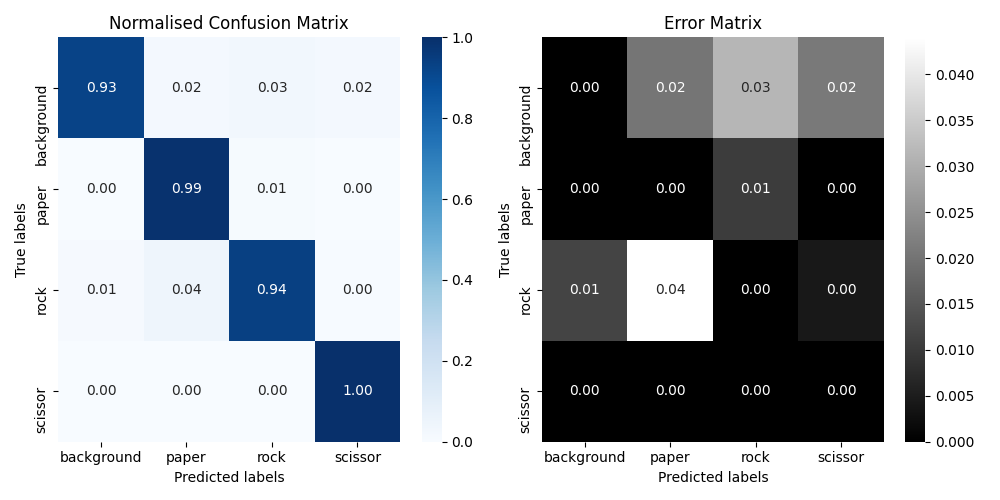
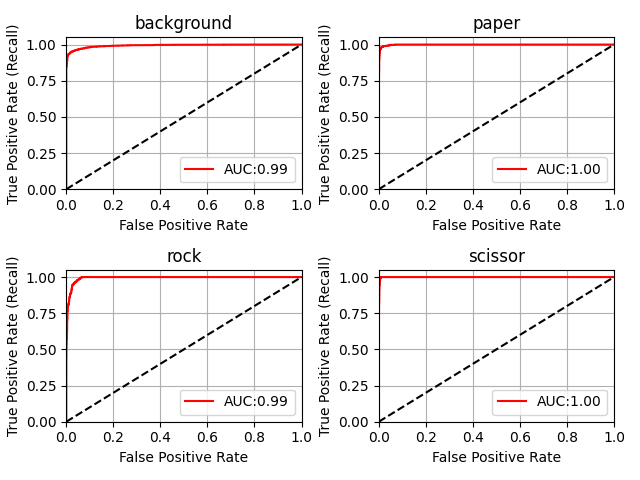
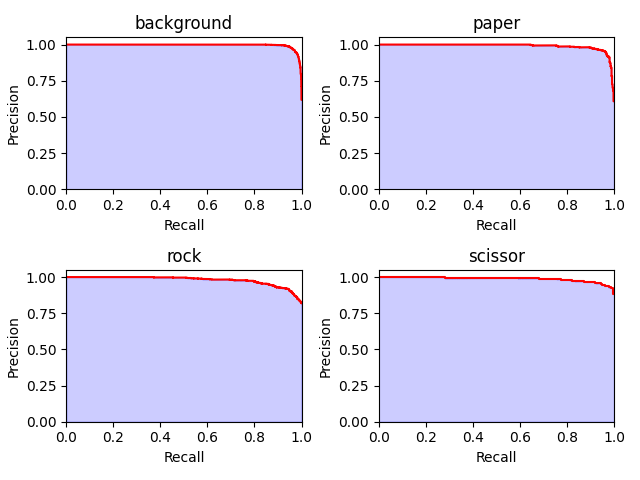
Inference
Once the model is trained, you can run inference test with our Python
sample classification_inference.py. It allows you to run live
inference with Prophesee EB camera, RAW/DAT recordings, and precomputed
HDF5 tensor files.
python classification_inference.py --help
usage: classification_inference.py [-h] [-p PATH] [--delta-t DELTA_T]
[--start-ts START_TS]
[--max-duration MAX_DURATION]
[--height-width HW HW] [-t CLS_THRESHOLD]
[--cpu] [-s SAVE_H5] [-w WRITE_VIDEO]
[--no-display]
[--max_incr_per_pixel MAX_INCR_PER_PIXEL]
[--max_low_activity_tensor MAX_LOW_ACTIVITY_TENSOR]
[--max_low_activity_nb_frames MAX_LOW_ACTIVITY_NB_FRAMES]
[--display_reset_memory]
checkpoint
Perform inference with the classification module
positional arguments:
checkpoint path to the checkpoint containing the neural network
name.
optional arguments:
-h, --help show this help message and exit
-p PATH, --path PATH RAW, HDF5 or DAT filename, leave blank to use a
camera. Warning if you use an HDF5 tensor file the parameters
used for pre-computation must match those of the
model. (default: )
--delta-t DELTA_T duration of timeslice (in us) in which events are
accumulated to compute features. (default: 50000)
--start-ts START_TS timestamp (in microseconds) from which the computation
begins. (default: 0)
--max-duration MAX_DURATION
maximum duration of the inference file in us.
(default: None)
--height-width HW HW if set, downscale the feature tensor to the requested
resolution using interpolation Possible values are
only power of two of the original resolution.
(default: None)
-t CLS_THRESHOLD, --threshold CLS_THRESHOLD
classification threshold (default: 0.7)
--cpu run on CPU (default: False)
-s SAVE_H5, --save SAVE_H5
Path of the directory to save the result in an HDF5
format (default: )
-w WRITE_VIDEO, --write-video WRITE_VIDEO
Path of the directory to save the visualization in a
.mp4 video. (default: )
--no-display if set, deactivate the display Window (default: True)
--max_incr_per_pixel MAX_INCR_PER_PIXEL
Maximum number of increments (events) per pixel. This
value needs to be consistent with that of the training
(default: 2)
--max_low_activity_tensor MAX_LOW_ACTIVITY_TENSOR
Maximum tensor value for a frame to be considered as
low activity (default: 0.15)
--max_low_activity_nb_frames MAX_LOW_ACTIVITY_NB_FRAMES
Maximum number of low activity frames before the model
internal state is reset (default: 5)
--display_reset_memory
Displays when network is reset (low activity)
(default: False)