
Quick Start from Training to Inference
In this section, we will walk through the steps required to create a simple trained model for object detection and use it.
We will:
download a dataset
convert the dataset to a format compatible with training
train a model
evaluate the obtained model
create a simple pipeline
We assume you have already installed Metavision SDK. If not, then go through the installation instructions.
Note that some parts of this tutorial are computationally intensive: training a model requires significant resources. We suggest using a computer with a dedicated GPU.
Warning
This tutorial will use a simple dataset, thus the resulting model will not reach the quality required for a real application and will not give representative results that can be obtained using machine learning on event-based data.
Dataset
The first step in any machine learning project is data collection. In this example, we will not collect the data ourselves, as this would require a significant amount of work. We will instead use a simplified mini-dataset (for larger-scale datasets, check the Recordings and Datasets page).
First download and unzip the dataset in a convenient directory on your computer (beware that this dataset, while called “mini”, is still 24G uncompressed, so make sure you have enough bandwidth and disk space).
The dataset consists of a JSON file and three directories, organized to facilitate training, validation and testing of machine learning models.
The JSON file label_map_dictionary.json provides the mapping between the classes present in the dataset
and their corresponding numerical IDs. This mapping is essential for associating labels with their
numerical representations during training and evaluation.
For example, in this dataset, the file contains the following content:
{
"0": "pedestrian",
"1": "two wheeler",
"2": "car",
"3": "truck",
"4": "bus",
"5": "traffic sign",
"6": "traffic light"
}
The dataset is divided into three directories, corresponding to the common practice of splitting data into:
Training (
train): used to train the model.Validation (
val): used to tune model hyperparameters and evaluate performance during training.Testing (
test): used to evaluate the final model’s performance on unseen data.
Each directory contains a set of paired files for every data record:
<record_name>.dat: contains the event-based data in DAT format
<record_name>_bbox.npy: contains the ground truth labels (bounding boxes), used for supervised training.
These files are examples of what you could obtain by recording your own data using Metavision Studio and creating the labels manually.
Now that we have a dataset, we need to convert the data in a format that is compatible with our ML tools.
Convert the dataset
Converting a dataset involves transforming event files (in RAW or DAT format) into tensors. Tensors are a structured, numerical representation of data that can be directly used for machine learning tasks. For more information on tensors, refer to the TensorFlow guide.
During this conversion process, the event-based data is preprocessed to ensure it is ready for efficient storage and computation. For a detailed explanation of the preprocessing steps, refer to the preprocessing chapter.
The converted data is stored in HDF5 tensor files, a format optimized for managing large amounts of structured data. You can find more information about this format in the :HDF5 tensor files page.
To convert the data, run the generate_hdf5.py script in each of the three data directories (training, validation, and testing):
cd <install-prefix>/share/metavision/sdk/ml/python_samples/generate_hdf5
python generate_hdf5.py /path/to/dataset/train/*.dat --preprocess histo -o /path/to/dataset/hdf5/train --height_width 360 640
python generate_hdf5.py /path/to/dataset/val/*.dat --preprocess histo -o /path/to/dataset/hdf5/val --height_width 360 640
python generate_hdf5.py /path/to/dataset/test/*.dat --preprocess histo -o /path/to/dataset/hdf5/test --height_width 360 640
Note that we use the histo preprocessing method to generate event histograms at a fixed frequency,
which are saved in the specified output directory. Ensure that you copy the label and dictionary files
(.npy and .labelfreq files ) to the same output directory so they remain accessible for training and evaluation
as well as the label_map_dictionary.json. You should now have an hdf5 folder with this structure:
$ tree -L 1 /path/to/dataset/hdf5
hdf5/
├── label_map_dictionary.json
├── test
├── train
└── val
Note
We scale the input data by a factor of 2 using the --height_width 360 640 option.
This scaling adjusts the data resolution while maintaining compatibility with the sensor’s original resolution constraints.
Note that only powers of 2 of the original sensor resolution are supported.
In this case, the sensor resolution is 720p (720 x 1280), scaling by a factor of 2 reduces the resolution to 360 x 640.
We can visualize the converted dataset using the viz_data.py script.
This will allow us to have a look at the dataset, verifying that it is opened correctly by our tools and that the ground truth is correct.
Add show-bbox to visualize the GT.
cd <install-prefix>/share/metavision/sdk/ml/python_samples/viz_data
python viz_data.py /path/to/dataset/hdf5 [--show-bbox]
This is an example of the output of viz_data.py:

Now we have the .h5 files which can be used for training.
Note
Some precomputed datasets for automotive detection are listed on the Datasets page and are available for download.
Training
Training can be performed using our pre-built training script, which includes a network topology specifically designed for object detection.
Before running a full training session, it’s a good practice to verify that your environment, dataset, and configurations are correctly set up. You can perform a debug run by training on a small subset of the dataset and running for only a few epochs.
For example, training on 1% of the dataset and running for two epochs allows for a quick validation to ensure everything is working as expected without committing significant time or resources:
cd <install-prefix>/share/metavision/sdk/ml/python_samples/train_detection
python train_detection.py /path/to/dataset/model_output /path/to/dataset/hdf5 --limit_train_batches 0.01 --limit_val_batches 0.01 --limit_test_batches 0.01 --max_epochs 2
Note
If the machine you are running this script on does not have a GPU, make sure to include the --cpu option in the command line.
This ensures that the script runs on the CPU, bypassing GPU-related operations and optimizing for the available hardware.
While this will work on systems without a GPU, note that training on a CPU will typically be slower than using a GPU.
This debug training run did not create any usable model, but it lasted only few minutes and can be a useful tool to avoid surprises.
Finally, we can run a complete training using train_detection.py with the following command:
cd <install-prefix>/share/metavision/sdk/ml/python_samples/train_detection
python train_detection.py /path/to/dataset/model_output /path/to/dataset/hdf5
This is an example of the console output. You can monitor the status of the training epoch and get KPIs at the end of each epoch. In this image you can see the KPIs of the epoch 1 and the progress of the epoch 2:

You can also supervise the training using TensorBoard by executing the following command and then opening http://localhost:6006/:
tensorboard --logdir <path to output directory>
This is an example of the TensorBoard page at the end of the training:
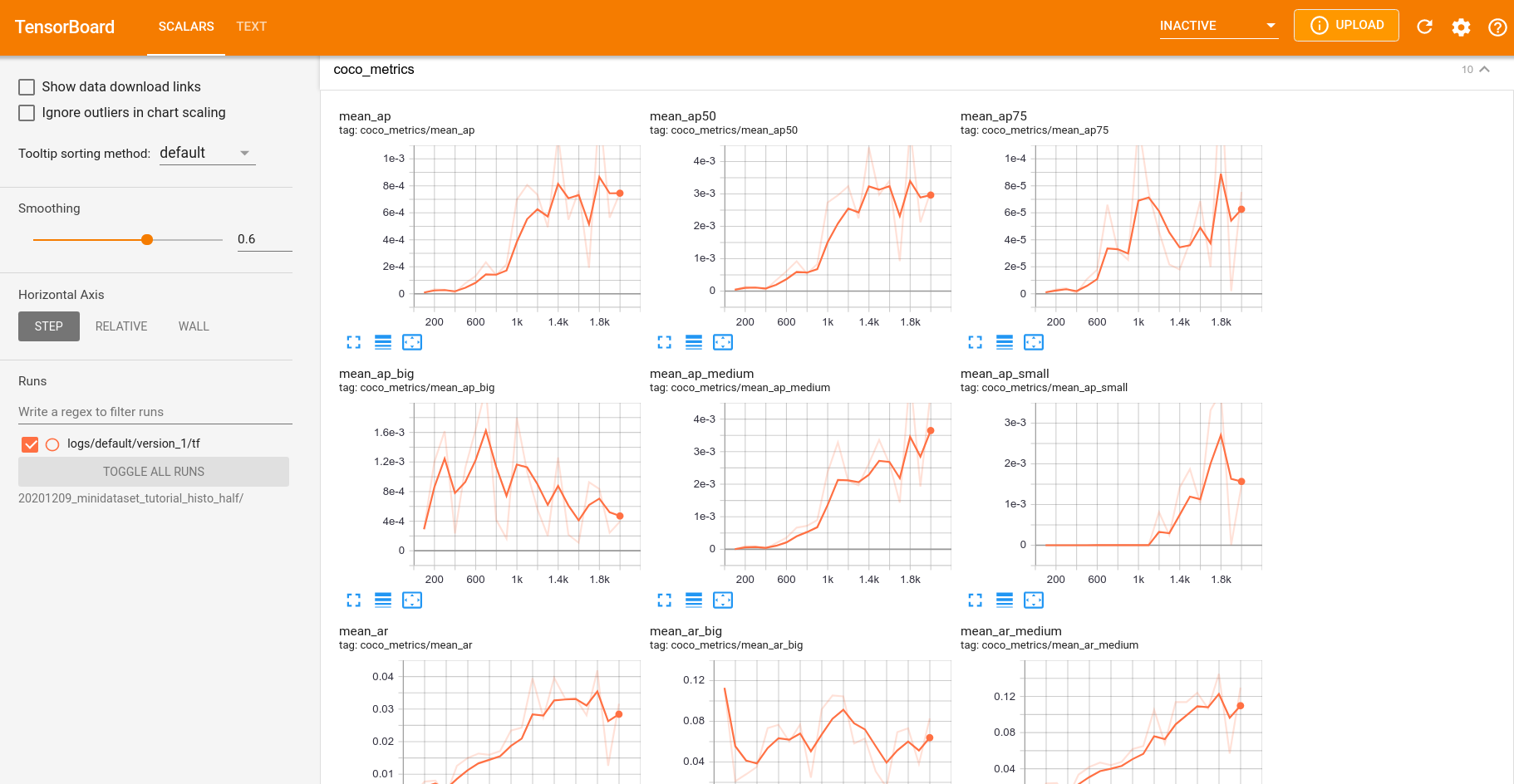
During training, and especially at its completion, the script will periodically generate checkpoints, which act as “save points” for the trained model. These checkpoints allow you to save the model’s state at various stages, making it possible to resume training if interrupted or to evaluate intermediate results.
Additionally, the script will produce videos showcasing a random selection of validation data. These videos provide a visual representation of the model’s performance, enabling you to observe its progress in tasks such as object detection or classification. This helps ensure that the training process is proceeding as expected and offers valuable insights into the model’s behavior on unseen data.
Once the specified number of epochs is completed, the training process concludes. The last generated checkpoint represents your final trained model, encapsulating all the learned parameters from the training session.
You can locate the final model, along with all intermediate checkpoints, in the directory /path/to/dataset/model_output/checkpoints
Finally, we can use our trained model in a pipeline.
You can use it in our sample Python pipeline or C++ pipeline.
To run our C++ pipeline:
First, export the model as a torchjit model with our script export_detector.py:
cd <install-prefix>/share/metavision/sdk/ml/python_samples/export_detector python export_detector.py /path/to/dataset/model_output/checkpoints/model.ckpt /path/to/dataset/model_torchjit/Launch the Metavision Detection and Tracking Pipeline (note that you need to compile it first as explained in the sample documentation)
Linux
metavision_detection_and_tracking --record-file /path/to/file.raw --detector-model path/to/dataset/model_torchjit/ --displayWindows
metavision_detection_and_tracking.exe --record-file /path/to/file.raw --detector-model path/to/dataset/model_torchjit/ --display
As you can observe, the results obtained are poor. This outcome is expected, as we are working with a very limited dataset consisting of only 4 training videos. With such a small amount of data, the network lacks the diversity and volume of information needed to effectively learn patterns and generalize to unseen data.
To achieve better results, it is recommended to use a larger dataset.
However, keep in mind that working with a larger dataset has additional requirements:
Storage: ensure you have sufficient disk space to store the dataset locally.
Processing Time: the training and preprocessing processes may take several hours, depending on the size of the dataset and the computational resources available.
Next steps
In this tutorial, we demonstrated how to use a labeled dataset to train a model and subsequently deploy the resulting model in a pipeline for object detection. This workflow showcases the potential of leveraging machine learning with event-based data to address real-world challenges effectively.
To maximize the potential of machine learning and event-based data, and to achieve optimal results tailored to your specific application, we encourage you to further explore the ML documentation. There, you will find advanced guides, best practices, and resources to fully utilize the power of Metavision ML.